A request que ninguém olhou
Abre o DevTools (F12) do teu navegador agora. Vai na aba Network. Atualiza qualquer página de um sistema que tu mantém ou já trabalhou. Olha a coluna de Status.
Tudo 200 OK? Atualiza a página. Tudo 200 novamente? Tudo voltando o payload inteiro? Parabéns, tu tá pagando banda, CPU e tempo de resposta pra entregar exatamente a mesma coisa que o navegador já tinha na mão dois segundos atrás.
Eu já vi isso em sistema grande, sistema pequeno, sistema de startup. É quase universal. E o motivo é sempre o mesmo: ninguém ensina cache HTTP. Ninguém. O pessoal aprende Redis antes de aprender ETag. Aprende a configurar uma CDN paga antes de aprender o que o navegador já faz de graça desde 1997, 30 anos atrás.
Hoje eu quero falar do 304 Not Modified. O status code mais subestimado da web.
O problema que fingem que nao existe.
Pede pro ChatGPT, Claude, Cursor, qualquer um deles: "como otimizo a performance da minha API?".
Aposto o almoço que a resposta vai vir com Redis. Talvez Memcached. Talvez uma CDN. Talvez um background job pra "pré-computar" alguma coisa. Provavelmente vai vir complexidade. Tudo isso faz sentido, mas a pergunta é: será que é a hora?
O que não vai vir, em 9 de 10 vezes, é a pergunta certa: "teu cache HTTP tá configurado?" Esse seria a primeira pergunta que qualquer pessoa com experiência faria antes de meter Redis num sistema que processa poucas requests por minuto.
A otimização mais cara é a que tu adiciona quando a de graça já existia.
O que é 304 Not Modified, sem enrolação
Funciona assim:
- Navegador pede um recurso pela primeira vez. Servidor responde 200 OK com o conteúdo e um header tipo ETag: "abc123" (é só um hash do conteúdo, pode ser qualquer identificador único).
- Da segunda vez em diante, o navegador manda a mesma request mas com um header novo: If-None-Match: "abc123". Tipo dizendo: "eu já tenho a versão abc123, ainda serve?".
- Servidor compara. Se o conteúdo não mudou, responde 304 Not Modified. Sem corpo. Sem JSON. Sem HTML. Só o status.
- Navegador usa o que ele já tinha em cache.
Latência cai. Banda cai. O servidor ainda processa a request, mas não precisa serializar nada, não precisa renderizar nada, não precisa mandar nada pelo fio. E em muitos casos, nem precisa bater no banco.
Custo de implementação no Rails: uma linha.
def show
@post = Post.find(params[:id])
fresh_when @post
end
É isso. fresh_when calcula o ETag a partir do updated_at do objeto, manda no header, e na próxima request compara automaticamente. Se o post não foi atualizado, Rails responde 304 antes mesmo de renderizar a view.
Uma linha. Não Redis. Nem gem nova. Nem configuração. Uma linha que o framework te dá há mais de uma década e que praticamente ninguém usa.
Quer ver na prática a diferença? Vamos usar o DevTools e carregar o index desse blog.
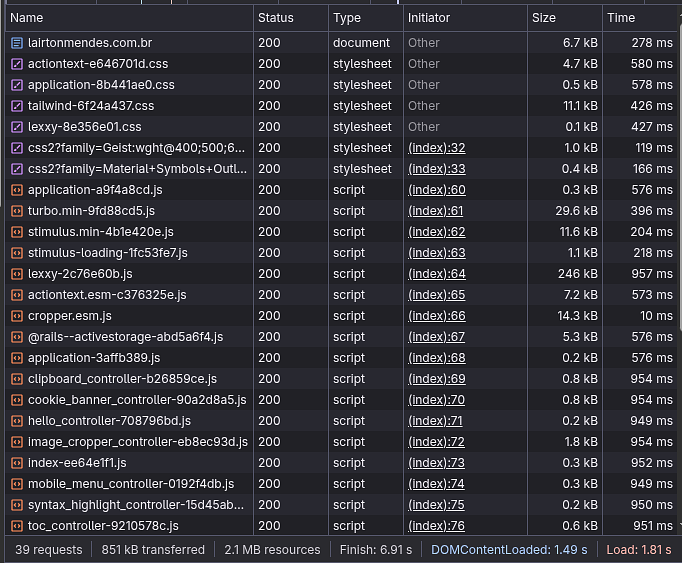
Vamos lá, aqui tem algumas particularidades para prestar atenção. Primeiro: 39 requests. Muitas? Não, para HTTP/2, que é o que hoje em dia é usado, definitivamente não. Segundo ponto importante e o que eu quero focar: 851 kB transferidos. Isso é pouco porque o blog é pequeno, tem poucos posts e coisas para carregar/baixar. Agora atualiza a página novamente.
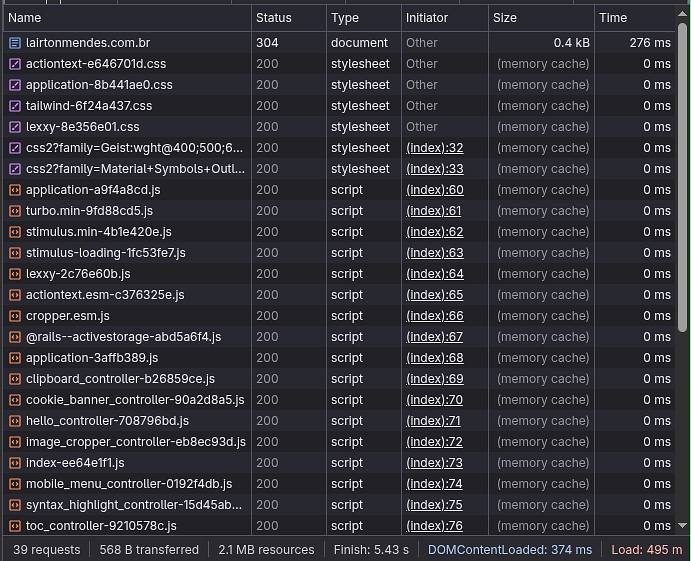
Na primeira linha, o status 304 foi onde a mágica do ETag aconteceu; antes foi baixado 6.7 kB; agora, com o servidor mandando somente o status 304 Not Modified, apenas 0.4 kB, uma economia de quase 95%. Isso foi só a primeira request. As outras requests com status "200"? Que request? Eles nunca foram feitas; foram cacheadas naquela primeira vez que carregamos a página. O servidor deu instruções para o browser fazer isso. O que se vê? Cache-Control de 1 ano.
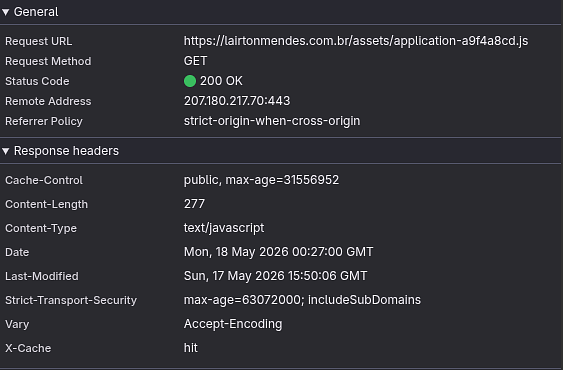
Mas aí fica a pergunta: é seguro fazer cache de um ano? Nesse cenário, com a estratégia que o Rails usa para entregar assets, total. Poderia fazer cache de 2, 3, 4 ou 10 anos. Tá vendo esse hash no final do arquivo? a9f4a8cd Isso é o fingerprint do arquivo: quando o arquivo mudar, o fingerprint vai mudar; ou seja, o cache vai ser automaticamente invalidado.
Agora, no total, em termos de banda de internet, saímos de 851 kB para 568 B, foram 99,93% de economia. Parece mágica, mas não é; é apenas o protocolo HTTP funcionando da forma como foi desenhado anos atrás.
Os três caches que ninguém distingue
Aqui tá a parte que confunde quem nunca parou pra estudar isso direito. Quando alguém fala "cache", pode ser uma de três coisas completamente diferentes, e elas não competem entre si, elas se complementam:
- Cache total no navegador — Cache-Control: max-age=3600. O navegador nem manda a request. Olha o relógio, vê que ainda tá dentro da validade, e usa o que tem em disco. Tempo de resposta: zero. Ideal pra assets (CSS, JS, imagens, fontes).
- Cache de validação — ETag + 304. A request vai até o servidor, mas se nada mudou, volta vazia. Ideal pra páginas e endpoints que mudam de vez em quando, mas não toda hora. Posts de blog, perfis, listas de produtos.
- Cache do lado do servidor — Redis, Memcached, Rails.cache. Tu evita a query no banco, evita o cálculo caro. Mas ainda renderiza, ainda serializa, ainda transfere pelo fio. Útil quando o gargalo é o backend, não a rede.
A maioria dos sistemas pula direto pro item 3 sem nunca ter passado pelo 1 e pelo 2.
Como isso parece num projeto Rails de verdade:
Imagina um blog (que conveniente). Um post tem updated_at. O conteúdo só muda quando eu edito. Entre edições, podem passar semanas.
Sem cache HTTP, toda visita roda:
- Roteamento
- Controller
- Query no banco (Post.find)
- Render da view (Markdown, syntax highlight, partials)
- Serialização do HTML
- Transferência pela rede
Com fresh_when @post, a partir da segunda visita do mesmo usuário (e dos crawlers que respeitam o cache, e dos proxies no
caminho), tudo isso vira:
- Roteamento
- Controller
- Query no banco (sim, ainda roda, é o trade-off)
- Comparação de ETag
- Resposta 304 vazia
Já cortou metade do trabalho. E se eu quiser cortar a query também, uso stale? Com um bloco e dou um jeito de pegar só o updated_at antes de carregar o objeto inteiro. Aí vira otimização de verdade. Sem dependência externa. Sem servidor novo. Sem operação a mais.
Onde 304 não resolve
Não vou ser igual aos vendedores de ilusão e dizer que 304 é bala de prata. Não é. Há casos em que simplesmente não dá:
- Página autenticada com conteúdo personalizado por usuário. Cuidado redobrado: tu precisa garantir que o cache não vaze dados de um usuário pro outro. Vary: Cookie, escopo certo, ETag que inclua o ID do usuário. Erro aqui é vazamento de dados, não bug de performance.
- Conteúdo em tempo real. Dashboard com métricas que atualizam a cada segundo? Cache HTTP atrapalha mais do que ajuda.
- POST, PUT, DELETE. Cache é pra leitura. Escrita não cacheia (e nem deve).
- APIs onde o cliente não respeita os headers. Tu manda ETag, o cliente ignora, manda request completa toda vez. Acontece com clientes mobile mal escritos, scripts de scraping, integrações antigas.
Cache HTTP brilha em conteúdo público ou semi-público que muda de vez em quando. Que é, vamos ser sinceros, a maior parte da internet.
Fechando
O 304 Not Modified não é um truque. Não é uma técnica avançada. Não é segredo de sênior. É o protocolo funcionando como foi desenhado pra funcionar há quase 30 anos. O que é raro é alguém parar pra usar.
Se tu tá começando, antes de aprender Redis, aprende HTTP. Antes de configurar uma CDN paga, configura Cache-Control. Antes de meter background job pra "pré-computar", testa se fresh_when resolve.
E se tu já é experiente e nunca olhou pra isso com carinho: abre o DevTools agora. Vai te doer ver quanto tráfego inútil tua aplicação tá servindo.
A internet rápida não foi feita de Redis. Foi feita de gente que entendeu o protocolo.


Ainda não há comentários. Seja o primeiro a comentar!
Deixe um comentário