A request que ninguém olhou
Open your browser's DevTools (F12) now. Go to the Network tab. Refresh any page of a system you maintain or have worked on. Look at the Status column.
Everything 200 OK? Refresh the page. Everything 200 again? Everything returning the full payload? Congratulations, you're paying for bandwidth, CPU and response time to deliver exactly the same thing the browser already had two seconds ago.
I've seen this in big systems, small systems, startup systems. It's almost universal. And the reason is always the same: nobody teaches HTTP caching. Nobody. People learn Redis before they learn ETag. They learn how to set up a paid CDN before they learn what the browser has done for free since 1997, almost 30 years ago.
Today I want to talk about 304 Not Modified. The most underestimated status code on the web.
The problem people pretend doesn't exist or don't even know exists
Ask ChatGPT, Claude, Cursor, any of them: "how do I optimize my API's performance?"
I'd bet lunch the answer will mention Redis. Maybe Memcached. Maybe a CDN. Maybe a background job to "pre-compute" something. Probably complexity. All of that makes sense, but the question is: is it the right time?
What won't come up, 9 times out of 10, is the right question: "is your HTTP cache configured?" That would be the first question anyone with experience would ask before dropping Redis into a system that processes a few requests per minute.
The most expensive optimization is the one you add when the free one already existed.
What 304 Not Modified is, no fluff
It works like this:
- Browser requests a resource for the first time. Server responds 200 OK with the content and a header like ETag: "abc123" (it's just a hash of the content, it can be any unique identifier).
- From the second time on, the browser sends the same request but with a new header: If-None-Match: "abc123". Like saying: "I already have version abc123, is it still valid?"
- Server compares. If the content hasn't changed, it responds 304 Not Modified. No body. No JSON. No HTML. Just the status.
- Browser uses what it already had in cache.
Latency drops. Bandwidth drops. The server still processes the request, but it doesn't need to serialize anything, doesn't need to render anything, doesn't need to send anything over the wire. And in many cases, it doesn't even need to hit the database.
Implementation cost in Rails: one line.
def show
@post = Post.find(params[:id])
fresh_when @post
end
That's it. fresh_when calculates the ETag from the object's updated_at, sends it in the header, and on the next request it compares automatically. If the post wasn't updated, Rails responds 304 before even rendering the view.
One line. No Redis. No new gem. No configuration. One line the framework has given you for over a decade and that almost nobody uses.
Want to see the difference in practice? Let's use DevTools and load this blog's index.
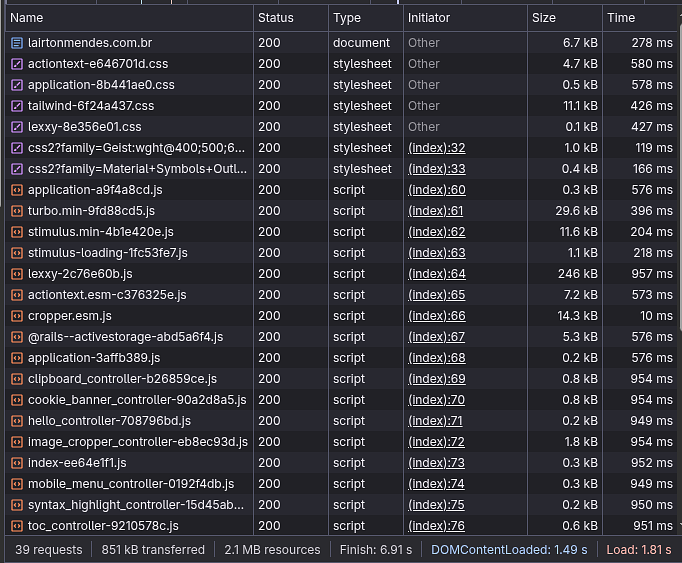
Okay, there are a few particulars to pay attention to. First: 39 requests. Many? No — for HTTP/2, which is what's used nowadays, definitely not. Second important point — and what I want to focus on: 851 kB transferred. That's small because the blog is small, with few posts and things to load/download. Now refresh the page again.
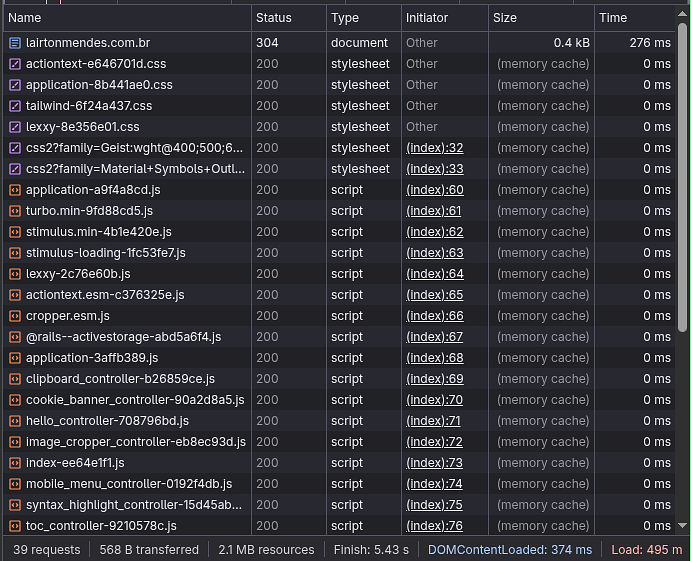
On the first line, the 304 status is where the ETag magic happened; before it downloaded 6.7 kB; now, with the server only sending the 304 Not Modified status, just 0.4 kB — a savings of nearly 95%. That was just the first request. The other requests with status "200"? What requests? They were never made; they were cached on that first time we loaded the page. The server instructed the browser to do that. What do you see? Cache-Control of 1 year.
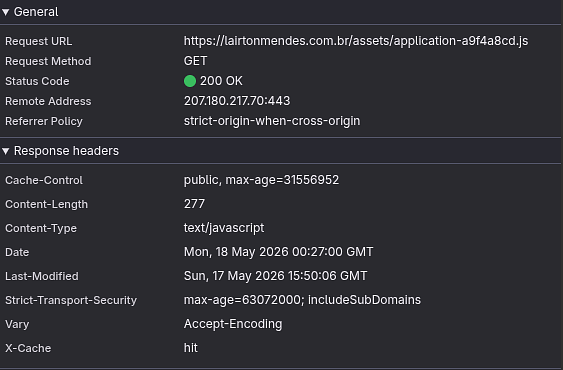
But then the question: is it safe to cache for a year? In this scenario, with the strategy Rails uses to deliver assets, absolutely. You could do 2, 3, 4 or 10 years. See that hash at the end of the file? a9f4a8cd That's the file fingerprint: when the file changes, the fingerprint changes; in other words, the cache will be invalidated automatically.
Now, in total, in terms of internet bandwidth, we went from 851 kB to 568 B — a 99.93% saving. It seems like magic, but it's not; it's just the HTTP protocol working the way it was designed to years ago.
The three caches nobody distinguishes
Here's the part that confuses people who never stopped to study this properly. When someone says "cache", it can be one of three completely different things, and they don't compete with each other, they complement each other:
- Total browser cache — Cache-Control: max-age=3600. The browser doesn't even send the request. It checks the clock, sees it's still valid, and uses what's on disk. Response time: zero. Ideal for assets (CSS, JS, images, fonts).
- Validation cache — ETag + 304. The request goes to the server, but if nothing changed, it comes back empty. Ideal for pages and endpoints that change occasionally, but not all the time. Blog posts, profiles, product lists.
- Server-side cache — Redis, Memcached, Rails.cache. You avoid the database query, avoid expensive computation. But you still render, still serialize, still transfer over the wire. Useful when the bottleneck is the backend, not the network.
Most systems jump straight to item 3 without ever having gone through 1 and 2.
What this looks like in a real Rails project:
Imagine a blog (how convenient). A post has updated_at. The content only changes when I edit it. Weeks can pass between edits.
Without HTTP cache, every visit runs:
- Routing
- Controller
- Database query (Post.find)
- View rendering (Markdown, syntax highlight, partials)
- HTML serialization
- Transfer over the network
With fresh_when @post, from the second visit by the same user (and by crawlers that respect cache, and by proxies along the
way), all of that becomes:
- Routing
- Controller
- Database query (yes, it still runs, that's the trade-off)
- ETag comparison
- Empty 304 response
You've already cut half the work. And if I want to cut the database query too, I use stale? with a block and manage to fetch only the updated_at before loading the whole object. Then it becomes a real optimization. No external dependency. No new server. No extra operation.
Where 304 doesn't solve
I'm not going to be like illusion peddlers and say 304 is a silver bullet. It's not. There are cases where it simply won't work:
- Authenticated pages with per-user personalized content. Double caution: you need to ensure cache doesn't leak one user's data to another. Vary: Cookie, correct scoping, an ETag that includes the user ID. A mistake here is a data leak, not a performance bug.
- Real-time content. A dashboard with metrics updating every second? HTTP cache will hurt more than help.
- POST, PUT, DELETE. Cache is for reads. Writes don't cache (and shouldn't).
- APIs where the client doesn't respect headers. You send an ETag, the client ignores it and sends the full request every time. Happens with badly written mobile clients, scraping scripts, old integrations.
HTTP caching shines for public or semi-public content that changes occasionally. Which, let's be honest, is the majority of the internet.
Closing
304 Not Modified isn't a trick. It's not an advanced technique. It's not a senior secret. It's the protocol working the way it was designed to work almost 30 years ago. What's rare is someone taking the time to use it.
If you're starting out, before you learn Redis, learn HTTP. Before you set up a paid CDN, configure Cache-Control. Before you add a background job to "pre-compute", test if fresh_when solves it.
And if you're experienced and never gave this some attention: open DevTools now. It'll hurt to see how much useless traffic your application is serving.
The fast internet wasn't built on Redis. It was built by people who understood the protocol.


No comments yet. Be the first to comment!
Leave a comment